Máquinas de Soporte Vectorial¶
Julián D. Arias Londoño¶
Profesor Asociado
Departamento de Ingeniería de Sistemas
Universidad de Antioquia, Medellín, Colombia
julian.ariasl@udea.edu.co
Consideremos nuevamente el problema de clasificación biclase a partir de un modelo lineal:
El conjunto de entrenamiento consta de \(N\) pares \(({\bf{x}}_i,t_i)\), donde \(t_i \in \{-1,1\}\) y las muestras nuevas son clasificadas con respecto al signo de \(y({\bf{x}})\).
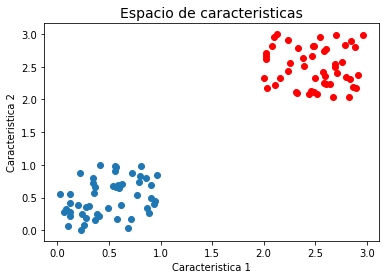
Supongamos que el problema es linealmente separable, es decir que las muestras de las dos clases están completamente separadas en el espacio de características:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
x1 = np.random.rand(2,50)
x2 = np.random.rand(2,50) + 2
plt.title('Espacio de caracteristicas', fontsize=14)
plt.xlabel('Caracteristica 1')
plt.ylabel('Caracteristica 2')
plt.scatter(x1[0,:], x1[1,:])
plt.scatter(x2[0,:], x2[1,:],color='red')
<matplotlib.collections.PathCollection at 0x7f82ab2ec810>
Podemos encontrar muchas fronteras diferentes que separan perfectamente las dos clases. Si utilizamos el criterio de minimizar el error de clasificación vamos a encontrar alguna solución que satisface el criterio:
import sys
sys.path.insert(0, './library/')
import svmclass as sv
sv.DecisionBoundaryPlot()
[[-0.17805303]
[-0.24795236]
[ 0.56327971]]
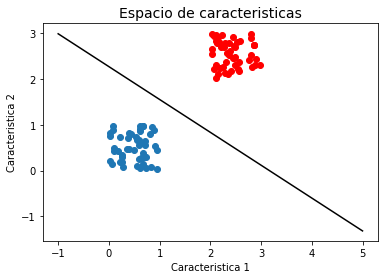
Sin embargo podríamos tener muchas otras fronteras, la pregunta que surge es ¿cuál de todas las posibles soluciones es la mejor?
Las Máquinas de Soporte Vectorial (En inglés Support Vector Machines) ) son un tipo de modelos de aprendizaje que permiten encontrar la mejor solución utilizando como criterio de ajuste la máximización del márgen, entendiendo márgen como la distancia más corta entre la frontera de decisión y cualquiera de las muestras.

Recordemos cómo se mide la distancia de un punto a un plano:
x1 = -1, 0
x2 = 1, 1
plt.scatter(*x1, s=300, marker='+')
plt.scatter(*x2, s=300, marker='+', color='r')
plt.plot([-.5,.5], [1.5,-.5], 'k-')
plt.plot([-1, 1], [-.5, 1.7], 'k--')
plt.annotate(r"$\bf{w}$", xy=(0.6, 1.5), fontsize=20)
plt.arrow(-1, 0, .1, -.2, fc="b", ec="b", head_width=0.07, head_length=0.1)
plt.arrow(1, 1, -.2, .37, fc="r", ec="r", head_width=0.07, head_length=0.1)
<matplotlib.patches.FancyArrow at 0x7f6f71a0c190>
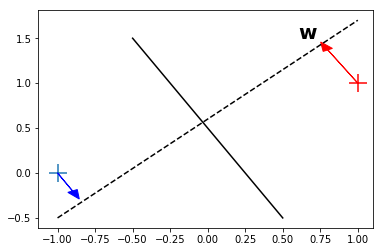
Teniendo en cuenta que la distancia perpendicular de un punto \(\bf{x}\) a un hiperplano definido por \(y({\bf{x}}) = 0\) está dado por \(|y({\bf{x}})|/\|{\bf{w}}\|\).
Sin embargo, si asumimos que todas las muestras están correctamente clasificadas, es decir, si \(t_n = -1\) entonces \(y({\bf{x}}_n)<0\) y si \(t_n=1\) entonce \(y({\bf{x}}_n) > 0\). Por lo tanto, en una solución en la que todos los puntos se encuentran bien clasificados se cumplirá que \(t_n y({\bf{x}}_n) > 0 \;\; \forall \;\; ({\bf{x}}_n, t_n)\).
Si asumimos entonces que todas las muestras están correctamente clasificadas, la distancia entre todos las muestras y la frontera de decisión estará dada por:
Por lo tanto la solución de máximo margen se encuentra resolviendo:
Aunque la función anterior corresponde a un criterio de entrenamiento de maximización del márgen, el proceso de optimización allí planteado es muy complejo. Por esa razón se debe encontrar una formulación alternativa.
Teniendo en cuenta que si se reescala el vector \(\bf{w}\) como \(k{\bf{w}}\) y \(b \rightarrow kb\), siendo \(k\) un valor real, la distancia \(\frac{t_n y({\bf{x}}_n)}{\|{\bf{w}}\|}\) sigue sin cambiar, se puede asumir que para el punto más cercano a la superficie \( t_n ({\bf{w}}^T\phi({\bf{x}}_n) + b)=1\) por consiguiente todos los puntos cumplirán la condición:
Entonces el término a minimizar en la función criterio anterior es igual a 1, por lo tanto ahora sólo se requiere maximizar \(\frac{1}{\|{\bf{w}}\|}\) o lo que es equivalente minimizar \(\|{\bf{w}}\|^2\). Usando los resultados anteriores la función de costo se puede escribir como:
Minimizar una función cuadrática sujeta a un conjunto de restricciones lineales se conoce como un problema de programación cuadrática.
Para solucionar el problema se introducen multiplicadores de Lagrange \(a_n \geq 0\), para cada restricción
Derivando con respecto a \(\bf{w}\) y a \(b\) e igualando a cero se obtienen las siguientes expresiones:
Reemplazando las dos expresiones anteriores, en la función criterio original se obtiene:
Usando la equivalencia \(\frac{1}{2}\|{\bf{w}}\|^2 = \frac{1}{2}{\bf{w}}{\bf{w}}^T\) y reescribiendo:
Sujeto a \(a_n \geq 0\), \(\sum_{n=1}^N a_n t_n = 0\)
Como se puede ver la función objetivo que se quiere optimizar no depende del vector de pesos \({\bf{w}}\), sino únicamente del producto \(\phi({\bf{x}}_n)^T \phi({\bf{x}}_m)\). La gran fortaleza de las SVM radica en que el producto punto anterior se puede reemplazar por cualquier función \(k({\bf{x}}_n , {\bf{x}}_m)\) que cumpla las condiciones de Mercer (Consultar).
Utilizar un producto punto diferente, significa aplicar una transformación del conjunto de características \(k({\bf{x}}_n , {\bf{x}}_m) = \phi({\bf{x}}_n)^T\phi({\bf{x}}_m)\), sin necesidad de conocer la transformación \(\phi(\cdot)\), únicamente el producto punto. El espacio al cual se mapean los datos puede ser de dimensión mayor que el original y es posible que clases traslapadas en el espacio original sean linealmente separables en el espacio transformado \(\phi(\cdot)\).
Uno de los kernels más comúnmente usados es el Gaussiano, el cual está dado por:
Pero existen muchos otros y existe también un conjunto de reglas que permiten definir nuevos kernels a partir de otros, por ejemplo usando operadores de suma y producto, entre otros (Consultar).
Usando la formulación anterior y resolviendo el problema de optimización cuadrático, la función de decisión se convierte en:
Y se satisfacen las siguientes condiciones:
De acuerdo con la tercera condición, para cada punto \({\bf{x}}_n\), se debe cumplir una de las siguientes dos opciones: su multiplicador de Largrange es \(a_n\) es igual a 0, ó el término \(t_n y({\bf{x}}_n)\) es igual a 1. En otras palabras, si una muestra se encuentra en el punto más cercano a la frontera \(a_n \neq 0\), de lo contrario \(a_n = 0\). Los puntos con \(a_n = 0\), no cuentan en la sumatoria de la función de decisión y pueden descartarse, los demás se conocen como vectores de soporte .

Esto implica que no es necesario almacenar todos los puntos sino únicamente los que el algoritmo de optimización seleccione como vectores de soporte. Una vez se hayan encontrado los valores de \(\bf{a}\), el valor de \(b\) se puede obtener fácilmente utilizando cualquier vector de soporte y reemplazando en la segunda restricción, \(t_n y({\bf{x}}_n)= 1 \). Sin embargo, una solución numérica más estable corresponde a usar todos los vectores de soporte y sacar un promedio de los diferentes \(b\) obtenidos:
donde \(N_{sv}\) es el número total de vectores de soporte.
Máquinas de Vectores de Soporte de Márgen suave¶
La formulación del modelo SVM hecho hasta ahora asume que las clases son separables, al menos en un espacio de alta dimensión. Sin embargo, las distribuciones de las clases pueden estar traslapadas y por consiguiente es necesario modificar la SVM para que permita que algunas muestras queden mal clasificadas. Lo que se hace entonces es permitir que las muestras se ubiquen en el lado incorrecto de la frontera pero aplicando una penalidad proporcional a la distancia a la frontera.
Se introducen en el modelo un conjunto de variables \(\zeta_n \geq 0\), conocidas como variables de relajación. Una para cada muestra \({\bf{x}}_n\). \(\zeta_n = 0\) para las muestras que se encuentran al lado correcto y \(\zeta_n = |t_n - y({\bf{x}}_n)|\) para las demás. Un punto ubicado justo en la frontera tendrá \(\zeta_n = 1\) y puntos con \(\zeta_n \geq 1\) estarán mal clasificados. Por último, puntos con \(0 \leq \zeta_n \leq 1\) caeran dentro del margen aunque en el lado correcto.
La restricción en este caso estará dada por:
y la función objetivo se convierte en:
$\(\min C \sum_{n=1}^N \zeta_n + \frac{1}{2}\|{\bf{w}}\|^2\)\( sujeto a \)\zeta_n \geq 0$
donde \(C\) controla el compromiso entre la penalidad de la variable de relajación y el margen. A este modelo se le conoce como Soft-margin SVM .
\(C\) se comporta como el inverso de un parámetro de regularización, \(C \rightarrow \infty\) corresponde a la SVM original. La función de optimización completa se convierte en:
donde \(a_n \geq 0\), \(\mu_n \geq 0\) son multiplicadores de Lagrange. Luego de realizar los procedimientos de derivación y reemplazo, similares a los del caso anterior se llegará a la función objetivo:
Sujeto a \(0 \leq a_n \leq C\), \(\sum_{n=1}^N a_n t_n = 0\)
Es posible entonces notar que la función objetivo es igual, únicamente cambió la restricción del proceso de optimización. Los vectores de soporte en este caso son aquellos puntos con \(0 < a_n < C\).
La predicción de una nueva muestra se realiza nuevamente a partir de
con
Que corresponden a las mismas expresiones de antes. Aunque es necesario tener en cuenta que la definición de los vectores de soporte en este caso es un poco diferente, debido precisamente al cambio en la restricción de la función objetivo.
Veamos algunos ejemplos prácticos utilizando la librería scikit-learn para python.
Creamos el conjunto artifical de datos
from sklearn import svm
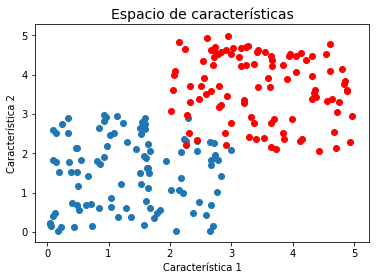
x1 = 3*np.random.rand(2,100)
x2 = 3*np.random.rand(2,100) + 2
plt.title(u'Espacio de características', fontsize=14)
plt.xlabel(u'Característica 1')
plt.ylabel(u'Característica 2')
plt.scatter(x1[0,:], x1[1,:])
plt.scatter(x2[0,:], x2[1,:],color='red')
<matplotlib.collections.PathCollection at 0x7fa81cfba250>
Definimos el kernel y entrenamos la SVM
X = np.concatenate((x1.T,x2.T),axis=0)
y = np.concatenate((np.ones((100,1)),np.zeros((100,1))),axis=0)
y = np.ravel(y)
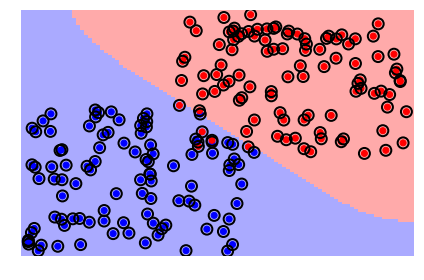
svc = svm.SVC(kernel='linear')
svc.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
Veamos la frontera de decisión y los vectores de soporte
plt = sv.plot_estimator(svc, X, y)
plt.scatter(svc.support_vectors_[:, 0],
svc.support_vectors_[:, 1],
s=120,
facecolors='none',
edgecolors='black',
linewidths=2,
zorder=10)
<matplotlib.collections.PathCollection at 0x7fa81cbcc9d0>
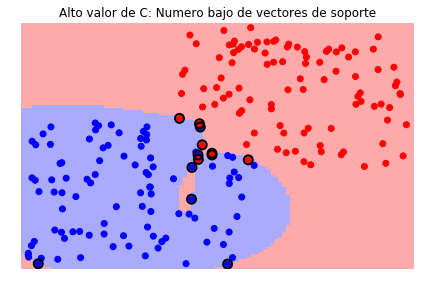
Veamos el efecto de \(C\)
svc = svm.SVC(kernel='rbf', C=1e6)
plt = sv.plot_estimator(svc, X, y)
plt.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1], s=80,
facecolors='none', edgecolors='black', linewidths=2, zorder=10)
plt.title('Alto valor de C: Numero bajo de vectores de soporte')
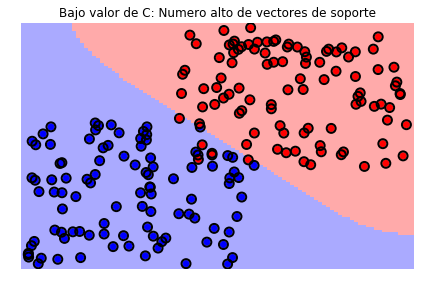
svc = svm.SVC(kernel='rbf', C=1e-2)
plt = sv.plot_estimator(svc, X, y)
plt.scatter(svc.support_vectors_[:, 0], svc.support_vectors_[:, 1], s=80,
facecolors='none', edgecolors='black', linewidths=2, zorder=10)
plt.title('Bajo valor de C: Numero alto de vectores de soporte')
Text(0.5,1,'Bajo valor de C: Numero alto de vectores de soporte')
Veamos ahora el efecto de la función kernel, en este caso la librería scikit-learn, como la mayoría de librerías de este tipo, trae varias funciones kernels que se pueden escoger e incluso se puede crear una función kernel particular y pasarla como argumento.
svc_lin = svm.SVC(kernel='linear')
sv.plot_estimator(svc_lin, X, y)
plt.scatter(svc_lin.support_vectors_[:, 0], svc_lin.support_vectors_[:, 1],
s=80, facecolors='none', edgecolors='black', linewidths=2, zorder=10)
plt.title('Kernel lineal')
svc_poly = svm.SVC(kernel='poly', degree=3)
sv.plot_estimator(svc_poly, X, y)
plt.scatter(svc_poly.support_vectors_[:, 0], svc_poly.support_vectors_[:, 1],
s=80, facecolors='none', edgecolors='black', linewidths=2, zorder=10)
plt.title('Kernel polinomial de grado 3')
svc_poly = svm.SVC(kernel='poly', degree=7)
sv.plot_estimator(svc_poly, X, y)
plt.scatter(svc_poly.support_vectors_[:, 0], svc_poly.support_vectors_[:, 1],
s=80, facecolors='none', edgecolors='black', linewidths=2, zorder=10)
plt.title('Kernel polinomial de grado 7')
svc_rbf = svm.SVC(kernel='rbf', gamma=1e2)
sv.plot_estimator(svc_rbf, X, y)
plt.scatter(svc_rbf.support_vectors_[:, 0], svc_rbf.support_vectors_[:, 1],
s=80, facecolors='none', edgecolors='black', linewidths=2, zorder=10)
plt.title('Kernel Gaussiano o RBF')
Text(0.5,1,'Kernel Gaussiano o RBF')
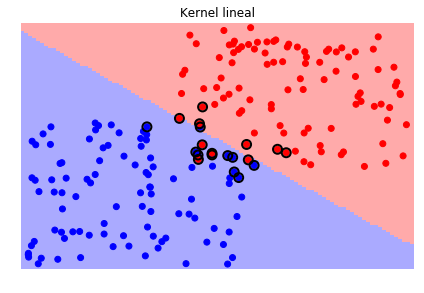
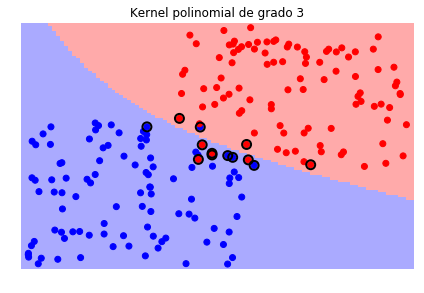
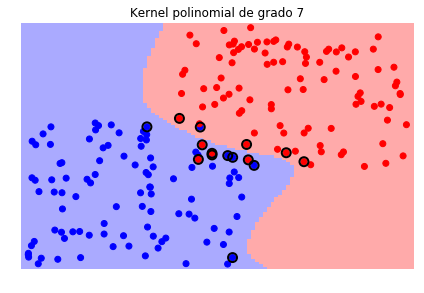
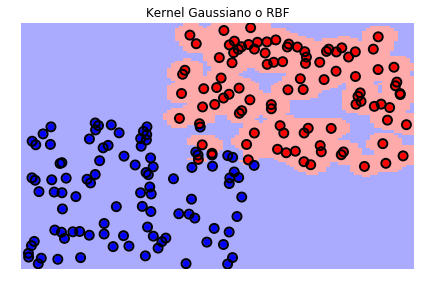
Es necesario tener en cuenta que durante el proceso de entrenamiento tendremos entonces que definir el valor del parámetro \(C\) y el o los parámetros del kernel que seleccionemos.
Regresión por vectores de soporte¶
El modelo de SVM descrito hasta el momento, puede ser extendido para resolver problemas de Regresión. En este caso, en lugar de minimizar una función de error cuadrático medio regularizada, es decir:
Se reemplaza por una función de error \(\epsilon\)-insensitiva:
Por consiguiente la función regularizada que se minimiza está dada por:
donde \(y({\bf{x}}_n) = {\bf{w}}^T \phi({\bf{x}}_n) + b\). Al igual que en el caso anterior, para permitir que algunas muestras caigan por fuera de la región deseada (\(\epsilon\)-tubo), se introducen variables de relajación. Sin embargo, en este caso es necesario introducir dos tipos de variables:

Cada muestra \({\bf{x}}_n\) debe garantizar las dos condiciones. Por consiguiente, la función de error para el modelo de regresión por vectores de soporte se puede expresar como:
La cual debe ser minimizada sujeto a las restricciones anteriores y a \(\xi_n^{+} \geq 0\) y \(\xi_n^{-} \geq 0\).
Para llevar a cabo el proceso de optimización con restricciones, se define la siguiente función objetivo a partir de los multiplicadores de Lagrange \(a_n^{+}\), \(a_n^{-}\), \(\mu_n^{+}\) y \(\mu_n^{-}\):
Derivando con respecto a \(\bf{w}\), \(b\), \(\xi_n^{+}\) y \(\xi_n^{-}\), e igualando a cero se obtiene:
Si al igual que se hizo para las SVM, se reemplazan los resultados anteriores en la función \(L\), la representación dual en este caso está dada por [1]:
Una vez más, teniendo en cuenta las derivadas con respecto a \(\xi_n^{+}\) y \(\xi_n^{-}\), y que ambas variables deben ser mayores o iguales a cero, se requiere que:
El resultado del proceso de optimización permitirá establecer las muestras que caen en el límite del \(\epsilon\)-tubo o fuera de él y las caen dentro. Se entiende que una muestra no puede estar al mismo tiempo por arriba y por debajo de la función objetivo, por lo que para cada muestra \(a_n^{+}\), \(a_n^{-}\) o ambos, deben ser cero.
La función a la salida se puede expresar como:
El parametro \(b\) puede ser calculado al reemplazar un vector de soporte en la ecuación anterior y garantizar que está fuera del \(\epsilon\)-tubo, es decir:
Al igual que en el caso de las SVM, en la práctica es mejor promediar el resultado para los diferentes vectores de soporte.
La siguiente figura muestra un ejemplo de frontera que puede ser obtenida usando una SVR con kernel RBF. Imagen tomada de: https://basilio.dev/screenshots.html

Veamos algunos ejemplos prácticos del uso de SVR.
from sklearn.svm import SVR
###############################################################################
# Generate sample data
X = np.sort(5 * np.random.rand(40, 1), axis=0)
y = np.sin(X).ravel()
###############################################################################
# Add noise to targets
y[::5] += 3 * (0.5 - np.random.rand(8))
###############################################################################
# Fit regression model
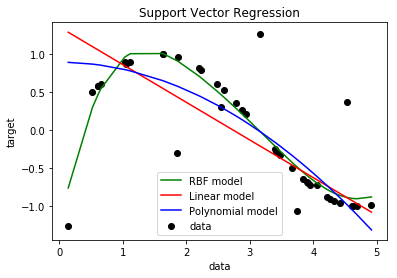
svr_rbf = SVR(kernel='rbf', C=1e3, gamma=0.1)
svr_lin = SVR(kernel='linear', C=1e3)
svr_poly = SVR(kernel='poly', C=1e3, degree=2)
y_rbf = svr_rbf.fit(X, y).predict(X)
y_lin = svr_lin.fit(X, y).predict(X)
y_poly = svr_poly.fit(X, y).predict(X)
###############################################################################
# look at the results
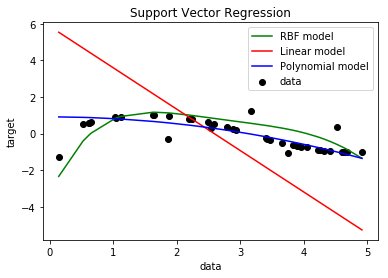
sv.PlotEjemploSVR(X,y,y_rbf,y_lin,y_poly)
###############################################################################
# Fit regression model
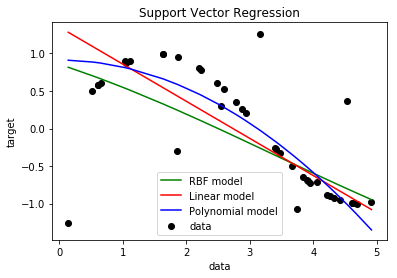
svr_rbf = SVR(kernel='rbf', C=1, gamma=0.01)
svr_lin = SVR(kernel='linear', C=1)
svr_poly = SVR(kernel='poly', C=1, degree=2)
y_rbf = svr_rbf.fit(X, y).predict(X)
y_lin = svr_lin.fit(X, y).predict(X)
y_poly = svr_poly.fit(X, y).predict(X)
###############################################################################
# look at the results
sv.PlotEjemploSVR(X,y,y_rbf,y_lin,y_poly)
###############################################################################
# Fit regression model
svr_rbf = SVR(kernel='rbf', C=1e7, gamma=0.01)
svr_lin = SVR(kernel='linear', C=1e7)
svr_poly = SVR(kernel='poly', C=1, degree=2)
y_rbf = svr_rbf.fit(X, y).predict(X)
y_lin = svr_lin.fit(X, y).predict(X)
y_poly = svr_poly.fit(X, y).predict(X)
###############################################################################
# look at the results
sv.PlotEjemploSVR(X,y,y_rbf,y_lin,y_poly)